




摸鱼阅读衍生出的一个插件
utools下载地址:utools官网
插件介绍
一个基于node的爬虫,用于爬取网络上各大阅读网站的书籍,并保存到本地txt文件。
单线程爬取,因为个人觉得爬快了也没多大用,会被封ip,还不如慢慢爬。
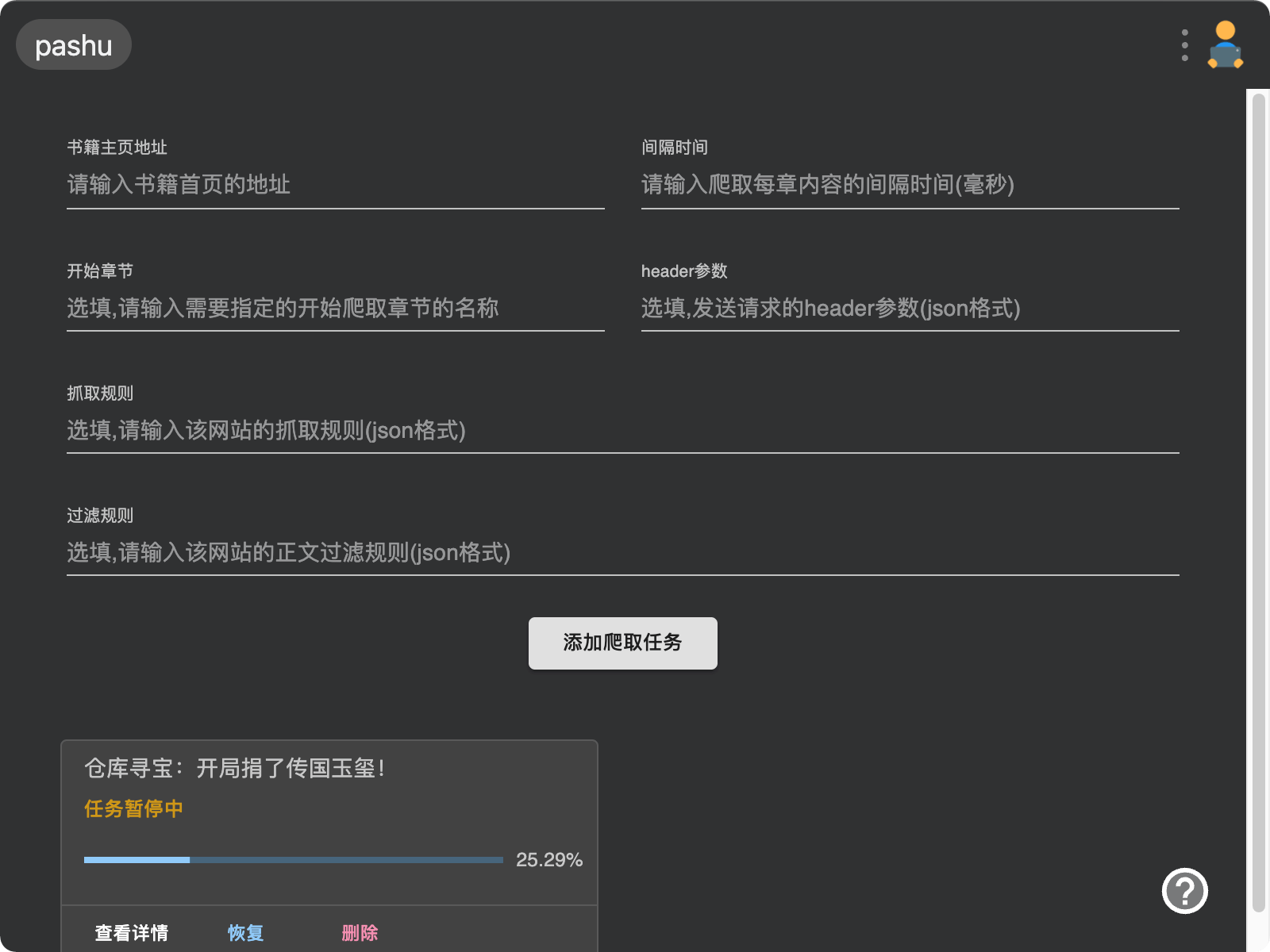
为什么做这个插件
开发摸鱼阅读后,要上班摸鱼的话先得找书籍资源,而很多网站并没有提供txt下载,所以想着做了这个爬虫,把书籍爬下来,再用摸鱼阅读来看。
开源
地址:https://github.com/luoxmc/scan-book
说明:我本身是做后端的,前端开发只是业余水平,所以代码很多地方写的比较粗糙,都还需要重构,各位大佬见笑了。
维护:爬书神器已经更新了多个版本,增加了多个功能,不过还有很多需求没有实现,比如爬取章节分多页的站、爬取手机版网站等,个人精力有限,没法完全投入开发,有兴趣的小伙伴可以实现功能后在github发起pr
工程相关
框架:
react + material-ui + cheerio
思路:
要实现一个爬取在线网站书籍的爬虫很简单,只需要自定义规则,并且按规则去爬对应的dom节点并且解析就行了。但是很多没有编程知识的朋友并不知道怎么去审查元素,怎么使用浏览器的开发者控制台,也就不知道怎么归纳整理网站爬取规则。而我在查看了十来个小说站的dom结构后,发现网站结构大同小异,所以我想着是不是能够预定义一些常见规则,以适配大多数的网站吗,能够自动爬取,不需要用户定义规则。所以在详细研究了数十个小说站的页面结构后,爬书神器这款插件就诞生了。
更新记录
1.3.1(2022-04-13 15:57:00)
- 暂停状态下的任务也可以保存了
- 优化智能爬取规则
1.3.0(2022-03-30 11:55:47)
- 支持配置代理池
1.2.3(2022-03-28 16:01:23)
- 增加新的爬取参数 - 结束章节
- 页面排版改造
1.2.2(2022-02-24 10:58:44)
- 插件开源
1.2.1(2022-01-12 10:31:53)
- 修复部分网站抓取正文出错的问题
- 支持更多网站
1.2.0(2022-01-07 10:00:56)
- 支持自定义开始爬取章节
- 支持设置请求header(方便爬取需登陆网站、付费章节等)
- 优化爬取下来的txt文件格式(保持换行、空格)
- 智能爬取逻辑优化
1.1.1(2022-01-04 14:54:36)
- 暂停或中断时将任务持久化到本地,完全退出插件后再进能继续任务
- 优化智能抓取逻辑
1.1.0(2021-12-31 08:52:40)
- 增加过滤规则,可以过滤正文内容
- 修复可能会保存失败的bug
- 增加“爬书神器”关键字
- 优化代码,越过部分网站的反爬机制
1.0.3(2021-12-29 14:27:42)
- 爬取中断时,增加跳过按钮,可以跳过当前爬取章节
1.0.2(2021-12-28 10:38:39)
- 修复多个可能导致爬取失败的bug
- 修复一直显示加载菊花的bug
1.0.1(2021-12-25 14:41:27)
- 修复自定义规则不生效的bug
- 修复提示保存失败的bug
1.0.0(2021-12-24 14:49:49)
- 爬书神器发布了,一起愉快的玩耍吧
其他
utools插件开发文档:
http://www.u.tools/docs/developer/welcome.html
luoxx阅读网
电脑上摸鱼用摸鱼阅读,平时手机上看小说还是要找各种资源,还有各种广告。所以我开发了一个阅读站,无广告,排版简洁,访问速度快,更新快,资源齐全(没有的书籍可以提交书单,博主会很快添加),网址是 https://read.luoxx.top 有需要的朋友可以尝试一下。 资源也是爬虫爬的,不同于爬书神器的node爬虫,luoxx阅读网使用的基于java的jsoup爬虫。 爬取的内容,每一本书都是结果博主严选的,错字乱码之类的情况会比较少。
高级选项
高级选项的设置有不会的可以在下方评论区留言,博主会尽快为你解答。比如:
-
如果有哪个网站无法智能爬取,而你又不知道怎么获取这个网站的爬取规则
-
不知道怎么定义header参数来爬取正版站
-
不知道代理池怎么设置
如果你觉得爬书神器还不错的话,欢迎在github项目主页点一颗star,在utools插件市场给爬书神器评一个五星好评哦,如果对这个插件有什么想法和建议,欢迎在博客下方评论区评论。


评论区