




语音合成哪家最强?毫无疑问的是微软,发音跟真人极其相似,读出来的句子有节奏感,停顿感。 but,but,微软api的收费实在是太贵了。免费的额度只有一丢丢,完全不够用嘛。所以只能退而求其次选择讯飞的语音合成。
需求
本人独立开发的 luoxx阅读网 , 最近想做一个听书的功能,将小说的章节通过语音合成api,转换成语音,实现可以在线听书的功能。讯飞的api每天可以免费调用500次,新注册搞上各种礼包还能陆续领到十几万次的调用次数,勉强还是够用的,毕竟我这个小网站用的人并不多哈。
方案踩坑
作为一个后端开发,最开始理所当然的选用了讯飞的java sdk,但是最后还是无奈放弃了。讯飞提供的java sdk真的是太辣鸡了。
- 文档模糊不清,不详细。
- 都2022年了,sdk包居然还没提供外部仓库依赖的方式(maven、gradle)
- 秘钥文件直接打在jar包里面,这是弄啥呢,闲得蛋疼不是
- 还需要依赖底层库(dll、so)并且文档里面根本没有解释清楚怎么使用,还要去百度寻求答案
- 返回的文件是pcm,要转mp3还得自己装ffmpeg
以上这些蛋疼的问题,并没有阻止我的脚步,无非就是麻烦点,一个一个解决罢了。然而等我全部跑通之后,第一次调用接口时,现实给了我无情的一击,我尼玛,三千多字的小说,调用一次api,差不多30-50秒才能完成,返回的pcm文件也有二十多兆。虽然转mp3之后文件可以压缩到3兆左右,但是我的小水管服务器,3兆也要5秒钟才能下载完成。而且ffmpeg从wav格式转成mp3也需要5秒钟左右。这整个过程加起来,差不多一分钟了。这谁受得了???
所以最终放弃了这种方案,改成使用webapi方案,前端直接调用,发websocket请求,实时接收数据,收到一点就播放一点,基本上不需要等待。
讯飞webapi接口文档: https://www.xfyun.cn/doc/tts/online_tts/API.html
服务端
使用webapi的方案,相当于前端直接调用,所以正常情况下,我们的appid以及秘钥也需要暴露在前端,这无疑风险极大。讯飞的webapi接口鉴权,其实就是把秘钥之类的东西经过各种混淆加密生成一个调用websocket的url,所以我想了个办法,在后端提供个接口生成调用的url,这样秘钥就不怕暴露了。
private static final String hostUrl = "https://tts-api.xfyun.cn/v2/tts";
private static final String apiSecret = "******";
private static final String apiKey = "******";
/**
* 获取讯飞webapi请求地址
*/
@RequestMapping("getXfUrl")
public JsonResponse getXfUrl(){
try {
URL url = new URL(hostUrl);
SimpleDateFormat format = new SimpleDateFormat("EEE, dd MMM yyyy HH:mm:ss z", Locale.US);
format.setTimeZone(TimeZone.getTimeZone("GMT"));
String date = format.format(new Date());
StringBuilder builder = new StringBuilder("host: ").append(url.getHost()).append("\n").//
append("date: ").append(date).append("\n").//
append("GET ").append(url.getPath()).append(" HTTP/1.1");
Charset charset = Charset.forName("UTF-8");
Mac mac = Mac.getInstance("hmacsha256");
SecretKeySpec spec = new SecretKeySpec(apiSecret.getBytes(charset), "hmacsha256");
mac.init(spec);
byte[] hexDigits = mac.doFinal(builder.toString().getBytes(charset));
String sha = Base64.getEncoder().encodeToString(hexDigits);
String authorization = String.format("hmac username=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"", apiKey, "hmac-sha256", "host date request-line", sha);
HttpUrl httpUrl = HttpUrl.parse("https://" + url.getHost() + url.getPath()).newBuilder().
addQueryParameter("authorization", Base64.getEncoder().encodeToString(authorization.getBytes(charset))).
addQueryParameter("date", date).
addQueryParameter("host", url.getHost()).
build();
String result = httpUrl.toString().replace("https","wss");
Map<String,Object> map = new HashMap<>(1);
map.put("url", result);
return JsonResponse.success().addResult(map);
} catch (Exception e) {
log.error("生成请求地址出错,错误信息:{}", e.getMessage(), e);
}
return JsonResponse.failure(2201,"获取失败");
}
前端代码
- 播放按钮标签(用的vuetify框架)
<v-btn small style="float: right;" class="mr-3" @click="playArticle" v-show="!audioStatus">
<v-icon left>mdi-music</v-icon>
播放此章
</v-btn>
<v-btn small style="float: right;" class="mr-3" @click="audioPause" v-show="audioStatus">
{{audioStatus === 'pause' ? '继续播放' : '暂停播放'}}
</v-btn>
- data 数据层
data () {
return {
article: {
articleContent: '测试讯飞语音合成api'
}
webSocket: null,
audioContext: null,
audioData: [],
bufferSource: null,
audioDataOffset: 0,
audioStatus: ''
}
}
- 播放此章按钮事件
讯飞webapi接口限制每次最多传13000个字节,并且传输的文本内容需要base64编码,所以字数很容易超标。我这边测试base64编码之前字符串保持在6000字节以下的话,base64编码之后长度也基本上是不会超过限制的。 超过6000字节的情况下,我这边做了截取,分两次发请求,再合并播放。超过12000字节的情况下,基本上字数是超过了五六千了,我这边直接拦截不发请求。因为调接口要收次数的,经不住几下这么玩。如果需要支持12000字节以上的话,自己改代码就行。
playArticle: async function (e,second) {
let str = this.article.articleContent.replace(/[\s]/g, "");
if (str.byteLength() > 12000) {
this.$message({type: "error", message: "本章字数过多,暂不支持播放"})
return
} else if (str.byteLength() > 6000) {
//超过6000字节,截取成两段, 对半分
let tmp = str.substring(0, str.length/2)
let index = Math.max(tmp.lastIndexOf("。"),tmp.lastIndexOf(","),tmp.lastIndexOf("?"),tmp.lastIndexOf("."),tmp.lastIndexOf(","),tmp.lastIndexOf("!"),tmp.lastIndexOf("!"))
//second 如果为true,表示为第二段文字的请求
if (index > -1) {
str = (second ? str.substring(index+1) : str.substring(0, index+1))
} else {
str = (second ? str.substring(str.length/2) : str.substring(0, str.length/2))
}
}
let response = await getXfUrl()
if (response && response.data.error_no === 0) {
let url = response.data.result.url
this.audioStatus = 'play'
let self = this
this.webSocket = new WebSocket(url);
this.webSocket.onmessage = (e) =>{
let resultData = e.data
let jsonData = JSON.parse(resultData)
// 合成失败
if (jsonData.code !== 0) {
self.$message({type: "error", message: "播放出错,请稍后再试"})
console.error(`${jsonData.code}:${jsonData.message}`)
self.audioStop()
return
}
let audio = Fun.transToAudioData(jsonData.data.audio)
self.audioData.push(...audio)
if (jsonData.code === 0 && jsonData.data.status === 2) {
self.webSocket.close()
}
}
this.webSocket.onopen = () =>{
let bs64 = Base64.encode(str)
let params = {
common: {
app_id: '7c6df9fc',
},
business: {
aue: 'raw',
auf: 'audio/L16;rate=16000',
vcn: 'aisjiuxu',
tte: 'UTF8',
speed: 68,
volume: 55,
pitch: 50
},
data: {
status: 2,
text: bs64
},
}
self.webSocket.send(JSON.stringify(params))
setTimeout(() => {
if (self.audioStatus === 'play' && !second) {
self.audioInit()
}
}, 1000)
}
this.webSocket.onerror = (e) =>{console.log(e)}
this.webSocket.onclose = (e) =>{
console.log(e)
//websocket关闭时,判断是否还有下一段,如果有第二段,则再次调用此方法
let lth = self.article.articleContent.replace(/[\s]/g, "").byteLength()
if (lth > 6000 && !second) {
self.playArticle(null,true)
}
}
} else {
this.$message({type: "error", message: "播放出错,请稍后再试"})
}
}
ps:getXfUrl 方法为调用后端接口获取讯飞url的代码
ps:base64数据处理需要import一下这个 import { Base64 } from 'js-base64'
ps:发送数据的时候,tte参数一定要传,写死 UTF8 即可,讯飞的文档中写的不需要传,默认值就是 UTF8 ,然而根本不是这样的,不传的话,返回的音频都是些乱七八糟的,跟送过去的文字完全对不上,传了 UTF8 即可正常播放,可见默认值根本不是 UTF8
- 结束播放(destroyed生命周期中可以调这个方法)
audioStop: function () {
this.audioStatus = ''
this.audioDataOffset = 0
if (this.bufferSource) {
try {
this.bufferSource.stop()
this.bufferSource = null
} catch (e) {
console.log(e)
}
}
this.audioData = []
this.audioContext = null
}
- 暂停播放与继续播放
audioPause: function () {
if (this.audioContext.state === "running") {
this.audioContext.suspend();
this.audioStatus = 'pause'
} else if (this.audioContext.state === "suspended") {
this.audioContext.resume();
this.audioStatus = 'play'
}
}
- 公用方法(音频数据处理的方法)
const Fun = {
transToAudioData: function(audioDataStr, fromRate = 16000, toRate = 22505) {
let outputS16 = Fun.base64ToS16(audioDataStr)
let output = Fun.transS16ToF32(outputS16)
output = Fun.transSamplingRate(output, fromRate, toRate)
output = Array.from(output)
return output
},
transSamplingRate: function(data, fromRate = 44100, toRate = 16000) {
let fitCount = Math.round(data.length * (toRate / fromRate))
let newData = new Float32Array(fitCount)
let springFactor = (data.length - 1) / (fitCount - 1)
newData[0] = data[0]
for (let i = 1; i < fitCount - 1; i++) {
let tmp = i * springFactor
let before = Math.floor(tmp).toFixed()
let after = Math.ceil(tmp).toFixed()
let atPoint = tmp - before
newData[i] = data[before] + (data[after] - data[before]) * atPoint
}
newData[fitCount - 1] = data[data.length - 1]
return newData
},
transS16ToF32: function(input) {
let tmpData = []
for (let i = 0; i < input.length; i++) {
let d = input[i] < 0 ? input[i] / 0x8000 : input[i] / 0x7fff
tmpData.push(d)
}
return new Float32Array(tmpData)
},
base64ToS16: function(base64AudioData) {
if (!base64AudioData) {
return
}
base64AudioData = atob(base64AudioData)
const outputArray = new Uint8Array(base64AudioData.length)
for (let i = 0; i < base64AudioData.length; ++i) {
outputArray[i] = base64AudioData.charCodeAt(i)
}
return new Int16Array(new DataView(outputArray.buffer).buffer)
}
}
export {
Fun
}
- 字符串字节数计算方法
String.prototype.byteLength = function() {
let count = 0;
for(let i=0,l=this.length;i<l;i++) {
count += this.charCodeAt(i) <= 128 ? 1 : 2;
}
return count;
}
其他
效果如图,字数较多的章节发了两次websocket请求,可以正常播放
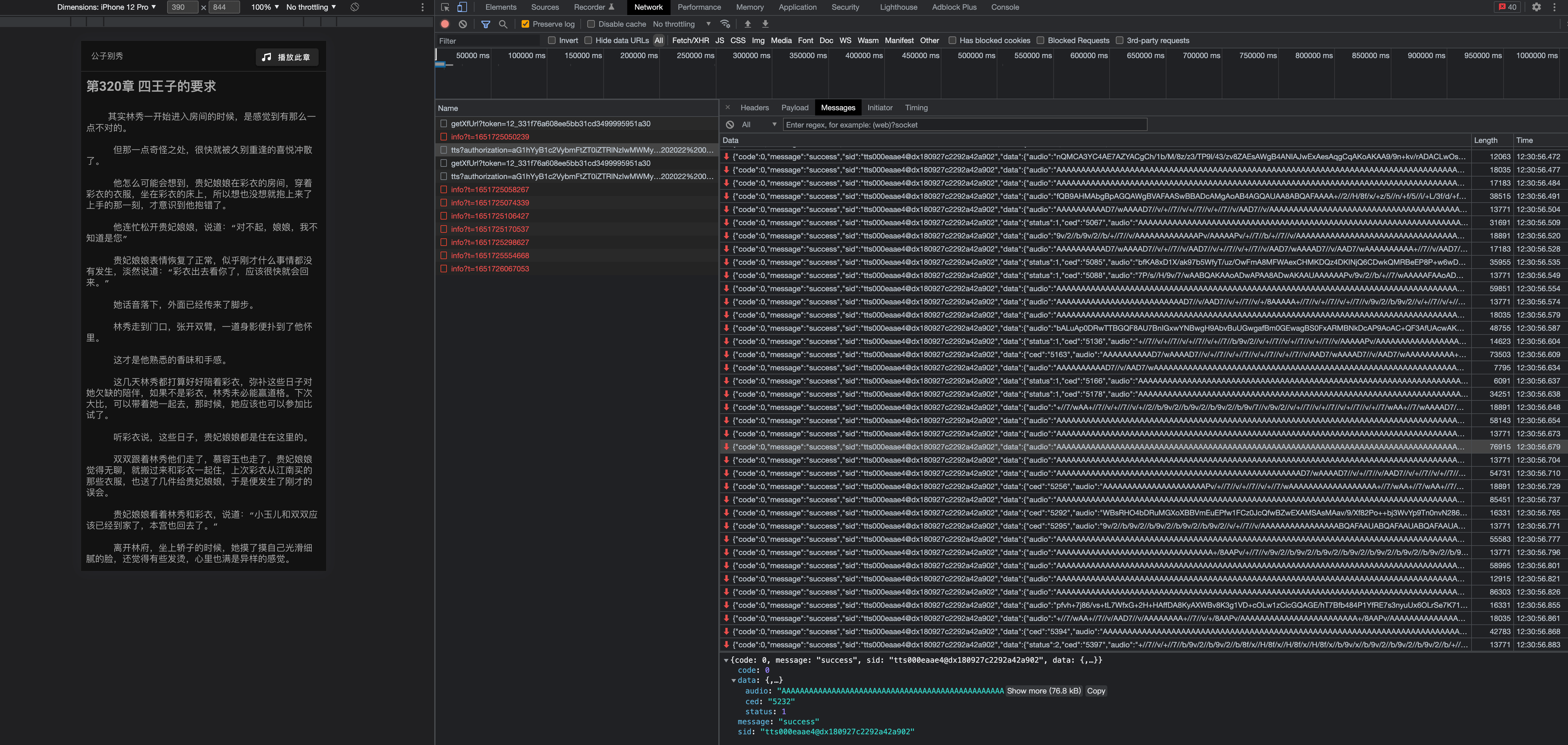
需要在线体验看效果的朋友可以去这个地址随便找本小说找个章节试一下 luoxx阅读网


评论区