




爬虫爬到的文章格式千奇百怪,格式一点都不整齐,非常不美观。前端需要特殊处理才能使文章内容格式整齐。
前言
jsoup爬虫从网页上爬到的文章内容,保存到数据库的之后才发现格式千奇百怪,基本上没办法通过单个正则表达式来概括并且完全格式化这些文章,所以只能在前端做处理,拿到文章内容后在前端代码里面把内容格式调整。
先列举一下数据库内各种千奇百怪的文章格式
-
第一行没有加tab的

-
文章最开始换行行数太多的
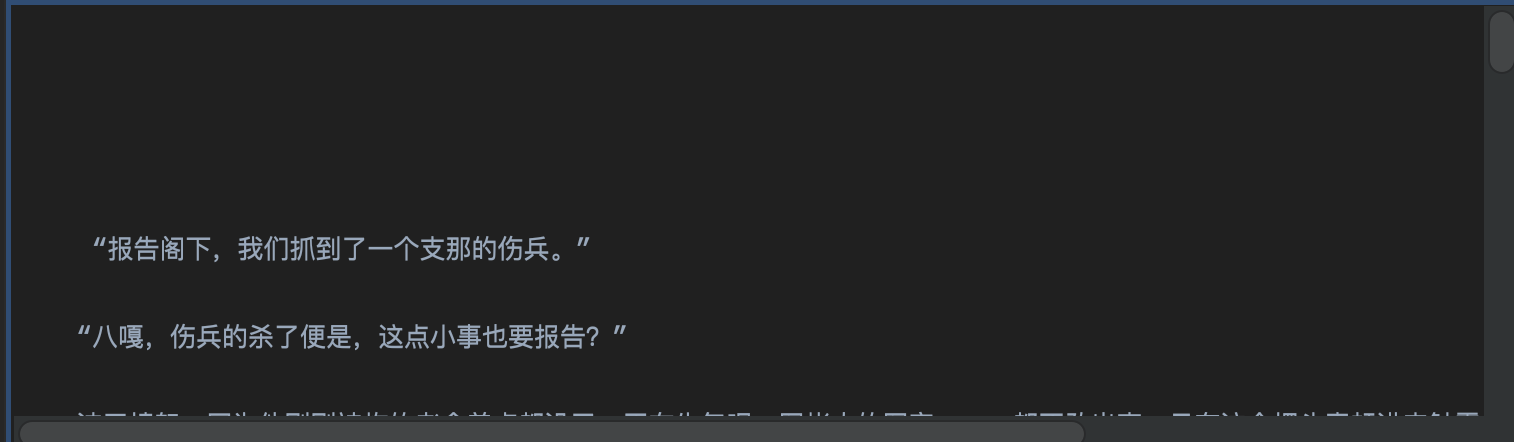
-
文章结尾换行行数太多的
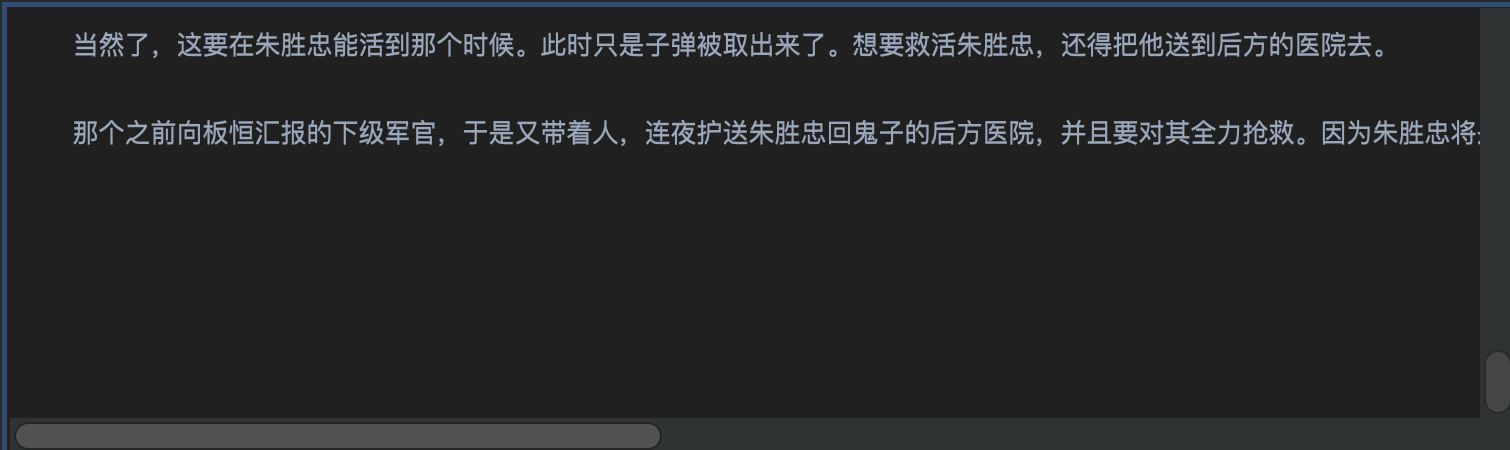
-
每个段落换行行数太多的
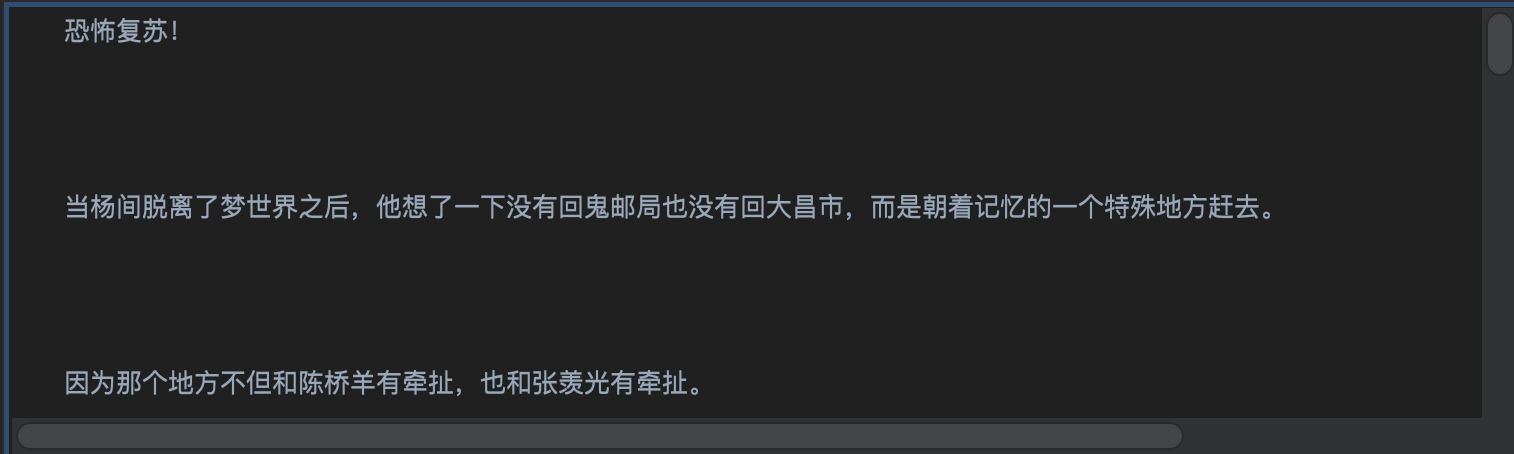
-
每个段落紧贴着换行太少的
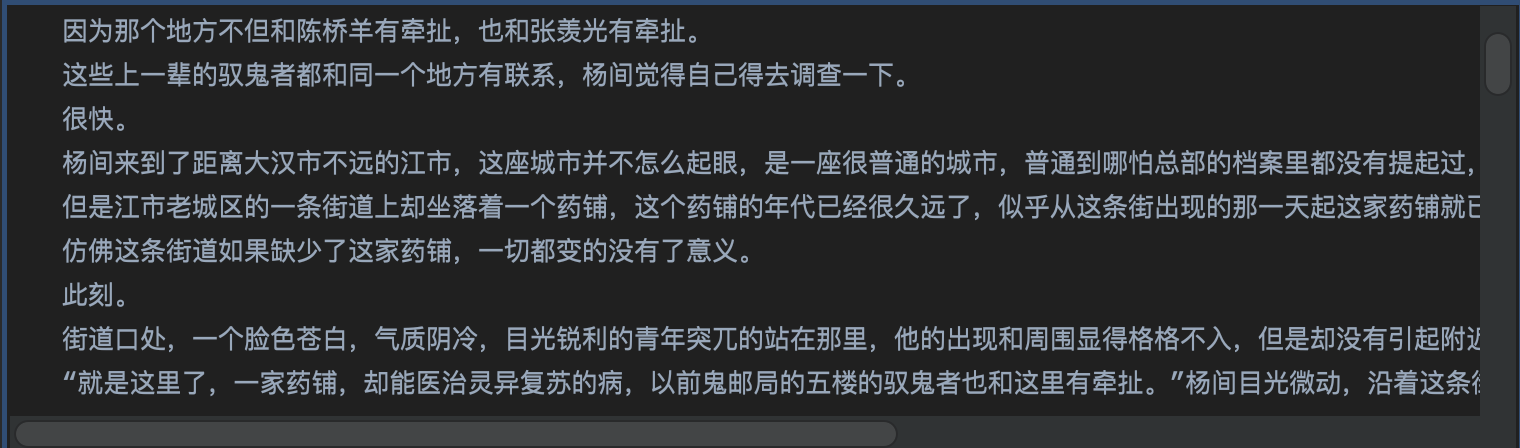
-
每个段落前面都没加tab的
-
每个段落前tab太多的
而我们正常的文章格式应该文章首尾不要换行,每段文字前只需要一个tab(四个空格),每段文字之间隔一个空行,效果如下

js处理格式
用js来处理这些千奇百怪的格式也是无奈之举,其实最好的办法还是爬取的时候就把格式处理好,然后再落库。
function parseContent (str) {
if (!str){
return ""
}
//把回车符替换为换行符,保持统一
str = str.replace(/\r/g,"\n");
//按换行符分割字符串,分割成很多个段落
let arr = str.split("\n")
//定义数组用于接收段落列表
let brr = []
//遍历,删除没有文字内容的空段落,并且将每个段落trim去除前后空白,再把每个段落前面拼四个空格
arr.forEach(function (o) {
if (o.trim()) {
brr.push(" " + o.trim())
}
})
//将所有段落用标准的换行连接起来
return brr.join("\n\n")
}
- 如上,执行完这个方法后的文章内容格式就是我要的效果了。
- 用split来处理也是我灵机一动想出来的办法,之前一直在想办法写出一个完美的正则表达式来替换格式不正常部分,结果花了很多时间也实现不了,而split再拼接的办法确非常好使。
- 使用这个方法必须要字符串里面有最基本上的分段,也就是说有
\n或者\r, 如果连基本格式都没有,所有内容都糊在一块的,那神仙也救不了。
结束
改造后的效果可以去我的阅读网站看下,现在的所有章节的内容都是非常标准美观的格式了
地址:https://read.luoxx.top


评论区