




摸鱼阅读上线utools插件市场后,有不少朋友关注和使用,博主也一直在迭代开发新的功能和修复各种bug,迭代至今已经将近一年时间了。
最近博主又花了较长一段时间苦肝出了一个全新的功能-支持阅读在线小说网站的书籍。这是一个非必须的功能,但是绝对是一个有意思的功能,开发也花费了博主很多时间和精力,所以这个功能将作为一个收费功能上架,希望有兴趣的朋友多多支持。
写在最前面
本插件不支持安卓开源阅读App的书源,只支持适配摸鱼阅读插件书源规则的书源,但是可以通过同步阅读App的书架书籍的方式阅读到所有阅读App能阅读的书籍。
ps:多说一句,书源在精不在多,目前插件有效的70多个书源,都是久经考验各有特色的网站,书籍覆盖情况不会比阅读App导入几千条书源后的效果差很多(因为几千条书源里面失效的占很大一部分,重复的同源的又占一部分,当然漫画书源除外,本插件不支持阅读漫画)。qq群里还经常有群友问咱们插件的书源能不能导到阅读App里面用,说还是我们的书源好用😂😂😂
交流群
摸鱼阅读用户交流qq群:658788121
utools下载地址
功能介绍
在线阅读功能其实就类似于安卓手机上的开源阅读app,添加各个网站的书源之后,就能在插件内搜索并且将书籍加到书架进行阅读。
-
书源管理的入口在插件右上角
-
打开书源管理后,在
添加书源输入框内填写在线书源的链接或者书源json文本,然后点击添加按钮即可添加成功。(不支持安卓开源阅读的书源)


-
添加书源成功之后,在插件主界面找到添加在线书籍入口
-
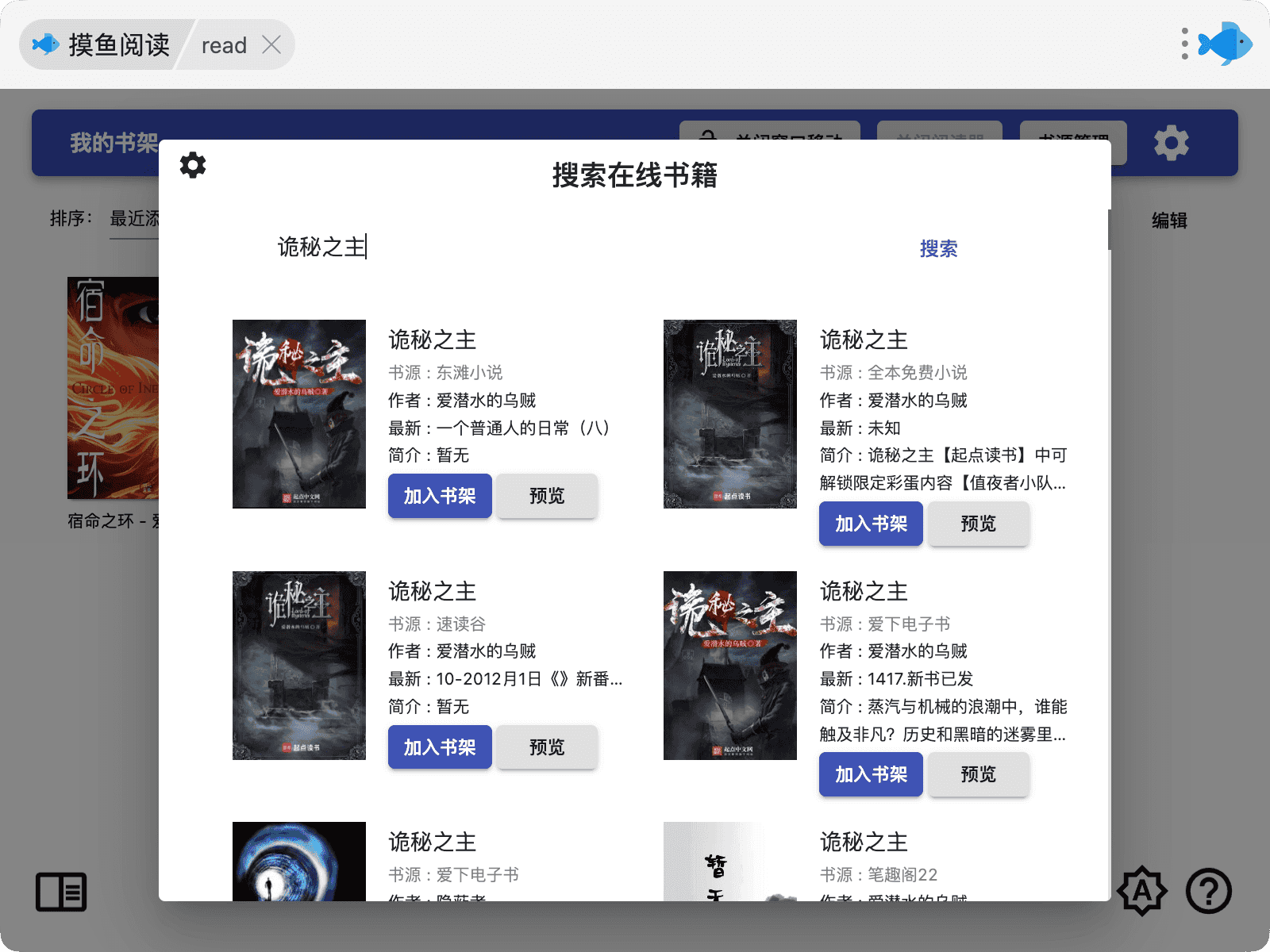
点击入口进入搜书界面后,输入关键字即可就开始搜书(点击搜索按钮或者直接按回车)
-
点击加入书架之后,即可在书架看到了,之后的操作就和本地书籍一样啦。
-
另外,本插件还支持同步安卓开源阅读APP的书架书籍,具体可以阅读 在摸鱼阅读插件中配置【开源阅读】服务 这一篇博客。
ps:搜索功能会在你已添加的所有书源内进行搜索,然后将所有书源的搜索结果展示出来,期间需要发网络请求到每一个书源对应的网站查询,所以会需要一点时间,请耐心等待。
ps:必须要重点解释一下,书源并不是指你要看小说的网站的网址,而是一串json数据,这串数据中定义了怎么去解析该网站的内容。直接在书源管理里面输入笔趣阁之类的网站的网址是不能添加上书源的。输入框描述的在线地址,比如摸鱼阅读官方书源https://www.luoxx.top/book_source.txt,这个地址其实就是一个在线的txt文件,文件的内容就是一长串json数据,里面包含了多个书源。
Cookie设置(非必须)
有一些网站部分章节需要登录后才能阅读(比如塔读),大部分正版网站的收费章节都需要登录并且购买后才能阅读(大半的正版站收费章节已加密,设置cookie也没法正常显示)。而绝大部分小说站的登录状态都是通过Cookie来保存的,所以,我们只需要在网页上登录好对应网站之后,保存一下存在浏览器的cookie,然后再书源管理中给对应网站的书源设置好cookie,即可在摸鱼阅读看到登录后才能完整阅读的章节。
具体操作如下,示例操作使用的是塔读(tadu.com)
- 第一步,在浏览器打开 tadu.com,点击右上角登录,登录好自己的账号
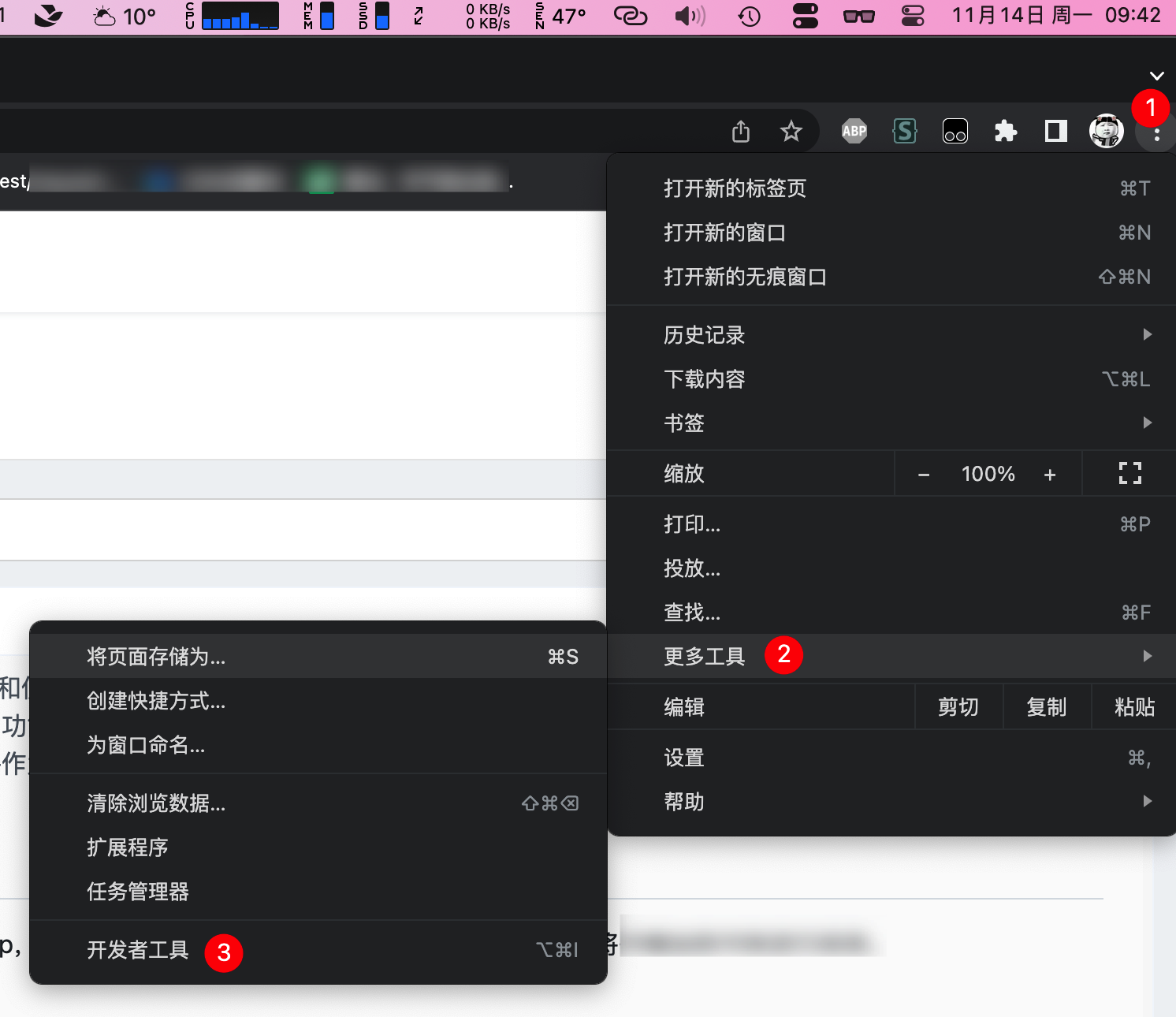
- 打开浏览器调试窗口(开发者工具) windows系统一般是按
f12,mac系统一般是command+option+i。也可以用鼠标操作,比如chrome浏览器的入口就是如图所在
- 打开之后刷新一下页面,然后切换到network标签,如图
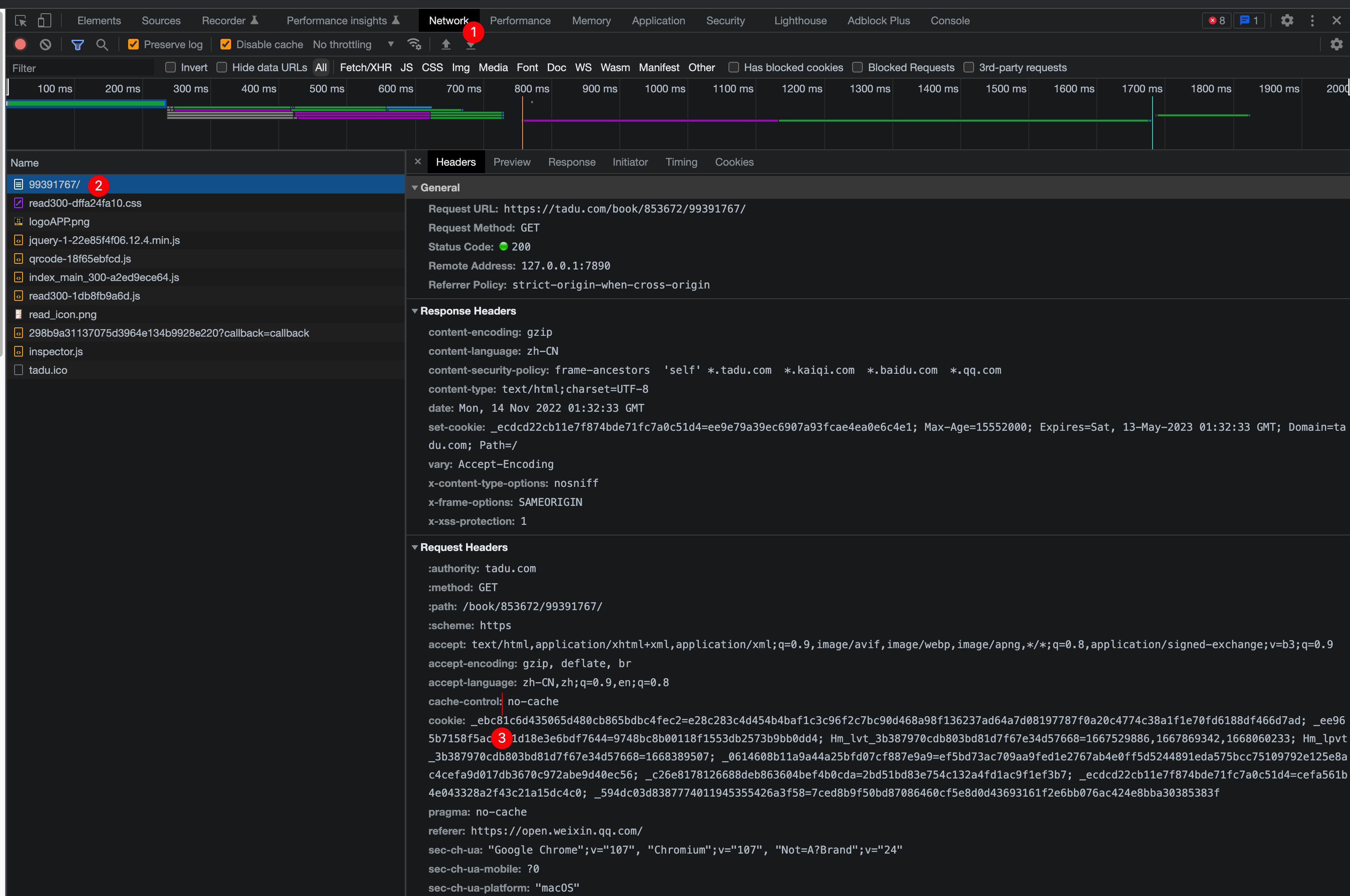
- 如上图,点击第一个网络请求,就能看到请求的详细参数,在Request Headers里面就有我们的cookie信息,将cookie的内容复制。
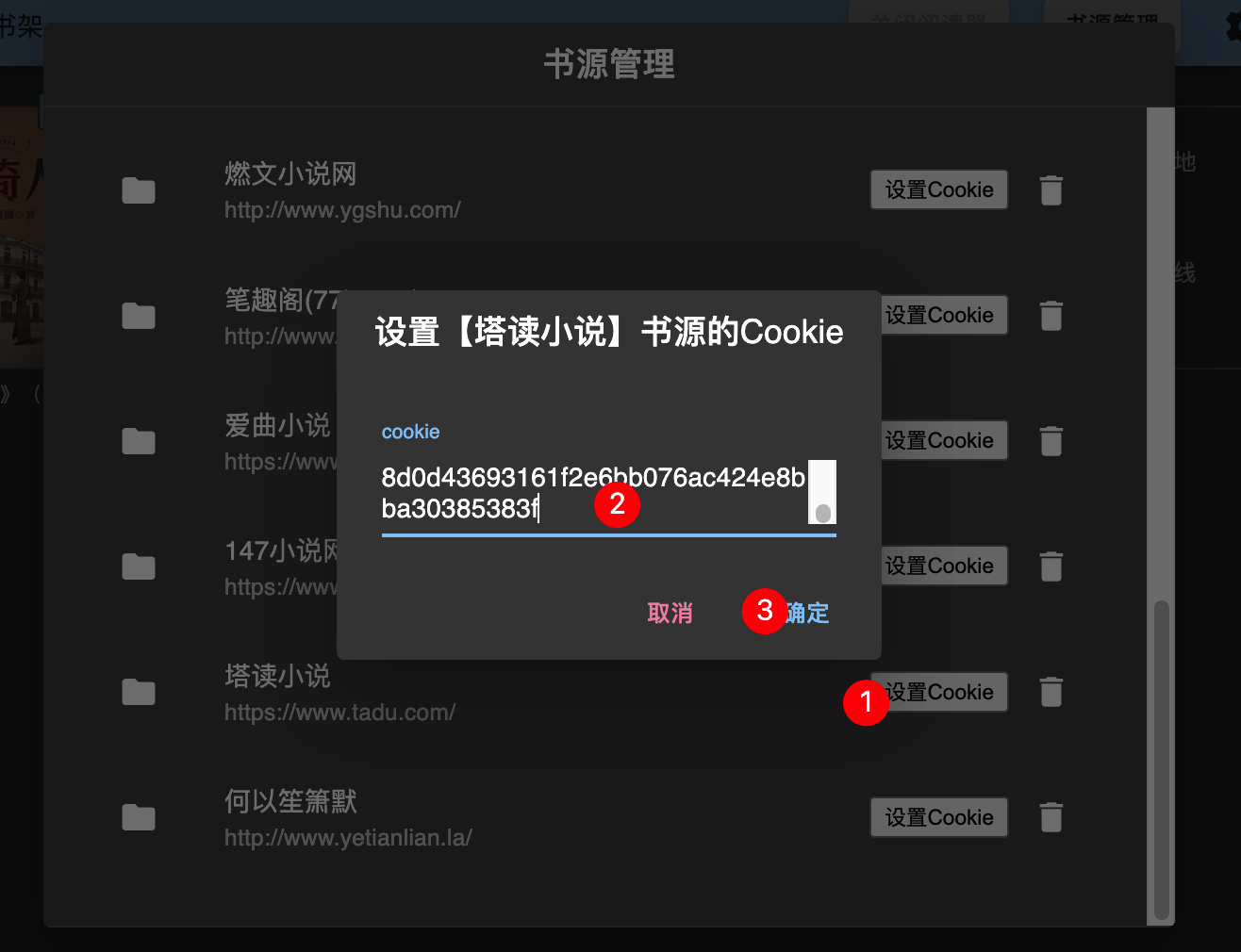
- 打开摸鱼阅读插件,点开书源管理,在书源列表内找到相应网站的书源,此处我们要找的是塔读的书源。
- 点击书源右边的设置cookie按钮,将我们复制的cookie内容填入,点击确定保存即可。
- 再次打开该网站的书籍,就能正常阅读登录后才能阅读的内容了。
在线阅读功能的优势何在
- 相比直接在浏览器网页看书,或者拿手机看书,使用摸鱼阅读看在线小说更隐蔽,被发现的风险低了不止一个数量级。
- 可以自定义净化规则,过滤掉网页上的广告以及一些垃圾的穿插内容(比如一秒记住本站地址之类的)
- 相比直接在插件添加本地书籍的方式,在线阅读添加到书架后,有新的章节直接就能看到,不用自己再去导入,时效性更高,更方便。
- 支持离线缓存章节,使用自己的手机热点批量缓存好要阅读的章节后,再切换回公司网络,就可以无忧摸鱼了,不用担心被公司网络监控到。
- windows、mac、linux三端都可用。
- 官方书源在维护的有效的书源达到
70+个,基本上覆盖了各种各样的书籍。 - 离线缓存的内容可以导出,所以你可以缓存一本书的所有章节,然后导出成完整的txt书籍,方便在其他地方阅读,比如手机上。
- 有一个任劳任怨的作者维护书源,相比自己到处找书源求书源,更加安心省事,有需求直接提给作者,简单方便。
- 支持了自动同步【开源阅读】书架,实现了多设备自动同步阅读进度,解决了书源较少的问题。
收费说明
在线阅读功能支持订阅购买,也支持买断式购买,对应价格如下:
| 类型 | 有效期 | 价格 |
|---|---|---|
| 1个月 | 30天 | 2元 |
| 6个月 | 180天 | 8元 |
| 12个月 | 365天 | 14元 |
| 永久授权 | 永久有效 | 28元 |
书源介绍
摸鱼阅读官方书源地址 https://luoxx.top/book_source.txt
置顶书源通知
- 原番茄书源已失效,新增加了可用的【番茄小说(legado)】、【番茄小说(utools)】书源,都是调用第三方网站提供的中转内容接口获取章节内容的,大家悠着点温柔一点用。
- 另外,如果你有番茄的svip会员,那么你可以使用【番茄小说(需开会员设置cookie)】这个书源阅读,只需要去官网 https://www.fanqienovel.com/ 登录账号,然后按本文教程获取cookie设置书源cookie即可,一次cookie大概能用两三天,过期了又需要重新设置。
- 新增了【七猫中文网(免会员)】书源,无需登录无需会员直接看七猫所有书籍,需要插件版本3.4.5及以上。
- 晋江书源,现在设置好自己账号的cookie就能正常阅读了,如果遇到部分字体不对的情况,需要等几十分钟或者一个小时再试。
- 番茄的书籍直接搜索手机版上的书名是搜不到的,请按照这个教程来搜索:番茄小说搜索教程
- 当你发现某个书源没法用时,不一定是书源失效,也可能是当前网络环境无法使用(摸鱼阅读的使用场景一般都是在公司,而公司的网络很多时候都会禁止访问小说相关网站),可以尝试切换网络(比如连手机热点)或者打开关闭代理再试试(有些网站需要开代理,而有些网站不能开代理开了反而禁止访问)。
官方书源已收录网站列表
ps:以下所列的是官方书源所收录的网站列表,不是书源地址,官方书源地址是 https://luoxx.top/book_source.txt
有效书源
- 何以笙箫默(http://www.yetianlian.net/ ) 热门网络小说
- 塔读小说(https://www.tadu.com/ ) 需在浏览器登录塔读账号,然后按教程获取登录后的cookie,设置到插件中
- 落霞读书(https://luoxiadushu.com/ ) 名著、文学、经典武侠,这个网站都是些很经典的书,质量很高
- 同人小说网(https://www.trxs.cc/ ) 不错的同人小说网站
- 飞卢小说网(https://b.faloo.com/ ) 飞卢正版小说
- 必去书库(http://www.biqusk.la/ ) 该网站不能使用境外代理,会被禁止访问
- 爱曲小说(https://www.biqusa.com/ ) 热门网络小说
- 云中书库(http://www.yunxs.la/ ) 该网站不能使用境外代理,会被禁止访问
- SF轻小说(https://s.sfacg.com/ ) 只能阅读免费章节,付费章节内容加密了无法获取
- 17k小说网(https://www.17k.com/ )
- 名著在线阅读网(https://guoxue.wunpu.com/ ) 名著文学作品阅读
- 飘天文学(https://www.piaotia.com/ ) 需配置www.piaotia.com域名科学上网才可访问,另外需要注意该网址只支持模糊搜索
- 耽美小说网(https://www.dmxs.org/ ) 女频小说
- 起点中文网(https://www.qidian.com/ ) 仅能阅读免费章节,收费章节加密了无法阅读
- 无极小说(http://wujixsw.cc/ ) 该网站不能使用境外代理,会被禁止访问
- 小说屋(http://www.xiaoshuoge.info/ ) 该网站不能使用境外代理,会被禁止访问
- 努努书坊(https://www.kanunu8.com/ )
- 文学吧(https://www.wenxue88.com/ )
- 飞速中文网(https://www.feibzw.com/ )
- 77书库(http://www.77shuku.org/ ) 该网站不能使用境外代理,会被禁止访问
- 笔趣阁(https://www.240789b.lol/ )
- 鬼吹灯小说网(http://www.cxzz958.com/ ) 该网站不能使用境外代理,会被禁止访问
- 52书库(https://www.52shuku.net/ )
- 酷我小说(http://appi.kuwo.cn) 不错的api书源
- 番茄小说(pc版)(https://www.fanqienovel.com/ ) 需开通svip后,设置登录后的cookie才可以阅读会员章节
- 番茄小说(legado)(https://novel.snssdk.com/ ) 搜索不到书籍时,请阅读搜索教程 -> https://luoxx.top/archives/fanqie-search-guide
- 番茄小说(utools)(https://novel.snssdk.com/ ) 搜索不到书籍时,请阅读搜索教程 -> https://luoxx.top/archives/fanqie-search-guide
- 言情小说库(http://www.yqk.net/ ) 女频小说
- 香书小说(http://www.xbiqugu.la/ )
- 无忧书城(https://www.wyshu.com/ )
- 精品小说网(https://www.jpxs123.cc/ )
- 笔趣阁小说(https://www.bqgnovels.com/ )
- 精品书屋(https://www.jingpinshuwu.top/ )
- 话本小说(https://www.ihuaben.com/ )
- 博爱书屋(http://www.bequgew.info/ ) 质量比较不错的书源,错字少
- 晋江文学城(https://m.jjwxc.net/ ) 需在浏览器访问https://m.jjwxc.net/,登录后获取cookie设置到本书源,才可阅读已购章节,该网站有反调试,请百度谷歌搜素(浏览器控制台禁止debug)找解决方案
- 有度中文网(https://www.yodu.org/ ) 需配置www.yodu.org域名科学上网才可访问
- 书海阁小说网(https://www.shuhaige.net/ )
- 五六中文网(https://www.56zw.com/ )
- 大熊猫文学网(https://www.dxmwx.org/ )
- 七猫中文网(免会员)(https://www.qimao.com/ ) 可直接阅读,无需会员无需登录无需设置cookie
- 旧钢笔文学(http://www.jiugangbi.com/ )
- 天章小说网(https://www.tianz.net/ )
- 笔趣阁22(https://www.22biqu.com/ )
- 爱下电子书(https://ixdzs8.com/ )
- 轻小说文库(https://www.wenku8.net/ ) 需要在网站上注册登录,然后在本插件内设置好登录后的cookie
- 溜达小说(http://www.liudatxt.la/ ) 该网站不能使用境外代理,会被禁止访问
- 乐阅读(https://www.27k.net/ )
- 米妮小说网(https://www.minixiaoshuow.com/ )
- 就爱言情小说网(https://www.92yanqing.com/ )
- 无弹窗完本耽美小说(https://www.fxshu.org/ ) 又名腐小说
- 八零书屋(https://www.8lsw.net/ )
- 速读谷(https://www.sudugu.org/ )
- 奇书网(https://www.qishuxia.com/ )
- 全本免费小说(https://www.qbmfxs.com/ )
- 东滩小说(http://www.dongtanxs.com/ )
- 和图书(https://www.hetushu.com/ ) 该书源搜索不到时,可以多试两次
- 00书(https://www.00shu.la/ )
- 30读书(https://www.30dushu.com/ )
- 疯读小说(https://touchlife.cootekservice.com/ ) 不错的api书源
- 米读看书(http://api.midukanshu.com/ ) 不错的api书源
- 爱看书(https://cxb-pro.cread.com/ ) 不错的api书源
- 多多书院(https://www.dmxs.org/ )
- 果露小说(https://www.dmxs.org/ )
- 亿软网(http://www.yiruan.info/ )
- UU小说网(http://www.uuwx.la/ )
- 中华典藏网(https://www.diancang.xyz/ ) 国学书籍网站,佛学、儒学、历史、诗词、天文地理等等经典书籍很全面
- 得间小说(https://wechat.idejian.com/ ) 该地址请勿使用境外代理,易触发滑块拼图验证。若搜索无结果或内容获取失败,在浏览器访问https://wechat.idejian.com/api/wechat/book/12052233/287,手动完成滑块拼图验证即可
- 幻梦轻小说(https://www.huanmengacg.com/ ) 该网站请不要使用境外代理,境外ip会触发防火墙验证
- 天涯在线书库(https://www.tianyabook.com/ )
- 哔哩轻小说 (https://www.bilinovel.com/ ) 挺不错的轻小说网站,以前失效了,最近废了老鼻子劲终于修复了
- 爱书包 (https://www.ishubao.org/ )
- 徽山书院 (http://www.weshan.com.cn/ )
- 无线电子书 (https://www.wxdzs.net/ )
- txt小说下载 (https://www.readtxt.com/ )
- 365小说网 (http://www.shukuge.com/ )
- 笔酷小说网 (https://www.bikuxs.com/ )
书源json示例
[
{
"source_name": "何以笙箫默",
"source_url": "http://www.yetianlian.la/",
"book_name": ".book .info h2",
"book_remark": ".book .info .intro",
"book_author": ".book .info .small span:eq(0)",
"book_cover": ".book .info .cover img",
"book_menu": ".listmain dl dd:gt(11) a",
"chapter_title": ".book .content h1",
"chapter_content_type": "1",
"chapter_content": "#content",
"content_filter": [
"NzAxN2s=",
"5LiA56eS6K6w5L2PLitjb20=",
"5Li+5oql5ZCO6K+36ICQ5b+D562J5b6FLOW5tuWIt+aWsOmhtemdouOAgg==",
"6K+36K6w5L2P5pys5Lmm6aaW5Y+R5Z+f5ZCNLitsYQ==",
"aHR0cC4raHRtbA=="
],
"multi_page": false,
"search_url": "http://www.yetianlian.la/s.php?ie=utf-8&q=###keyword###",
"search_result": {
"limit": "6",
"list": ".so_list .type_show .bookbox",
"name": ".bookinfo .bookname a",
"author": ".bookinfo .author",
"newest": ".bookinfo .update a",
"remark": "",
"cover": ".bookimg a img",
"cover_attr": "src",
"url": ".bookinfo .bookname a",
"url_attr": "href"
}
},
{
"source_name": "塔读小说",
"source_url": "https://www.tadu.com/",
"book_name": ".bookNm .bkNm",
"book_remark": ".boxT .intro",
"book_author": ".bookNm .author",
"book_cover": ".bookImg img",
"book_menu": ".boxT .lfT li div a",
"chapter_title": ".read_details_box .chapter h4",
"chapter_content_type": "2",
"chapter_content_attr": "value",
"chapter_content": "#bookPartResourceUrl",
"content_filter": [
"e1snIl1jb250ZW50WyciXTpbJyJd",
"WyInXX0k",
"LirloZTor7vlsI/or7QuKlxu"
],
"multi_page": false,
"search_url": "https://tadu.com/search?query=###keyword###",
"search_result": {
"limit": "8",
"list": ".seach_box .bookList li",
"name": ".rtList .bookNm",
"author": ".rtList .condition .authorNm",
"newest": "",
"remark": ".rtList .bookIntro",
"cover": ".bookImg img",
"cover_attr": "data-src",
"url": ".bookImg",
"url_attr": "href"
}
},
{
"source_name": "笔趣阁(77hr.org)",
"source_url": "http://www.77hr.org/",
"book_name": "#info h1",
"book_remark": "#intro p:eq(1)",
"book_author": "#info p:eq(0) a",
"book_cover": "#fmimg img",
"book_menu": "#list dl dd:gt(8) a",
"book_menu_attr": "href",
"chapter_title": ".box_con .zhangjieming h1",
"chapter_content_type": "1",
"chapter_content": ".box_con .zhangjieTXT",
"content_filter": [
"LS0mZ3Q7Jmd0O++8iOacrOeroOacquWujO+8jOivt+eCueWHu+S4i+S4gOmhtee7p+e7remYheivu++8iQ==",
"aHR0cC4raHRtbA==",
"56yU6Laj6ZiBLivnrKwuK+eroC4rXG4iLCJcXChodHRwLitcXClcbg==",
"MeenkuiusOS9j+mhtueCueWwj+ivtOe9ke+8mnjjgILmiYvmnLrniYjpmIXor7vnvZHlnYDvvJp4"
],
"multi_page": true,
"next_btn": ".box_con .zhangjieTXT .bottem a",
"next_val": "下一页",
"search_url": "http://www.77hr.org/search?searchkey=###keyword###",
"search_result": {
"limit": "5",
"list": "#alistbox",
"name": ".info .title h2 a",
"author": ".info .title span",
"newest": ".info .sys li a",
"remark": ".info .intro",
"cover": ".pic a img",
"cover_attr": "src",
"url": ".pic a",
"url_attr": "href"
}
}
]
书源json字段解释
如上例子可以看到,书源格式为一个json数组
[],每一个书源对应数组中的一个元素{}
下面详细解释一下每个字段的含义
ps:本书源的元素全部使用 css选择器 或者说jquery选择器来识别。
source_name 书源名称,本插件的书源以书源名称为唯一标志,所以尽量不要使用太简单的名称,比如笔趣阁,就可以命名为 【笔趣阁(biquge.com)】
source_url 对应网站的网址
book_name 书籍首页(展示所有目录的页面)书名元素的css选择器
book_remark 书籍首页书籍简介元素的css选择器
book_author 书籍首页作者元素的css选择器
book_cover 书籍首页书籍封面元素的css选择器,定位到img标签
book_menu 书籍首页目录列表css选择器,定位到a标签(一般来说是a标签,当然不是的话,以实际为准)
book_menu_attr 目录列表中的每一个章节元素的链接所在属性,一般都是a标签,所以一般都是href属性
chapter_title 章节阅读页面,章节标题元素css选择器
chapter_content_type 章节阅读页面,章节内容获取类型 1、直接获取(拿到元素后执行.text()方法) 2、拿到元素之后只能从元素上拿到一个链接,需要额外请求这个链接获取
chapter_content 章节阅读页面,章节内容元素css选择器
chapter_content_attr 如果chapter_content_type为2,则需要该字段,含义为获取资源的链接取chapter_content节点的哪个属性,一般是href
content_filter 章节内容过滤规则,该字段为一个数组,可以填入多个过滤规则,支持正则表达式。为了避免部分特殊字符影响json格式,所以过滤关键字全部采用base64编码。阅读器会将能匹配上过滤规则的内容全部移除,一般用于过滤到页面上的垃圾文字。
multi_page 是否为多页模式,就是说是一章内容全部在一页还是一章分几页的,true表示分页,false表示不分页。分页的书源会增加很多次请求,如非必要尽量不要用。
next_btn 如果为分页模式,则需要此字段,含义为:下一页元素的css选择器
next_val 如果为分页模式,则需要此字段,含义为:下一页元素的文字内容,一般都是“下一页”
search_url 搜书链接,网站的搜索地址,搜索关键字替换词为###keyword###,比如塔读的搜索地址为https://tadu.com/search?query=###keyword###
search_result 搜索结果解析格式规范,具体如下
搜索结果解析格式
limit 数量限制,该书源每次搜索最多展示的结果数量,因为很多网站搜索结果很多,随便一搜就是几十上百的个结果,跟关键字关联较大的一般也就前几个,所以设置了该字段,默认为10
list 搜索结果列表css元素,必填。 比如 #searchList ul li
name 书名元素。 从每个单独的搜索结果开始定位层级,前面的层级不用填,比如完整的css选择器是#searchList ul li .title h1 ,那么此处只填.title h1 即可,以下字段同理
author 作者元素
newest 最新章节元素
remark 书籍简介元素
cover 封面元素
cover_attr 封面元素取链接的属性attr,一般为src
url 书籍链接元素
url_attr 书籍链接的属性attr,一般为href
url_type 搜索结果点击后跳转的类型。 可不填,不填默认使用类型1。 1、点击后直接跳到了完整目录页 2、点击跳转之后的页面不是目录页,但是路径替换部分文字之后就是目录页的情况 3、点击跳转之后的页面不是目录页,但是路径后追加指定文字之后就是目录页的情况 4、前三种无法实现的情况,需要跳转之后才能从页面上拿到目录页地址的情况。
url_replace_rules 路径替换规则。 url_type为2时必填,示例: book%%list 此例中表示将路径中的book替换为list,如果有多个替换规则,用&&连接。
url_suffix 路径后缀。 url_type为3时必填,示例: /MenuList 此例表示原路径为https://a.com/12345/index,最终会转换成https://a.com/12345/index/MenuList
url_redirect 搜索结果跳转后页面的目录页选择器。示例: #bookList 此例表示获取到的url跳转之后的页面内去获取#bookList对应的元素的属性(url_attr)即为目录页的地址
search_url字段拓展
搜索地址最开始可以定义url的属性,用两个大括号框起来,可选属性如下
302 搜索地址不是最终结果页的情况,而是经过了一层302跳转
gb2312 搜索地址的关键字使用的是gb2312编码来encode的情况
escape 搜索地址的关键字使用的是escape函数来encode的情况
示例 {{302}}{{gb2312}}https://www.trxs.cc/e/search/index.php?keyboard=###keyword###&show=title&classid=0
常见问题
- 搜索不到书籍
请检查网络情况,尝试一下在本机书源当中的各个网站是否能正常访问。 - 已购买在线支付功能,但是不久之后再使用发现又要购买
这个是因为utools那边的改动导致的,明明还登录着utools账号,但是实际上登录状态已经失效了(简而言之就是utools的一个bug)。只需要退出重新登录即可,重新登录之后即可正常使用。请不要重复购买,重复购买者凭支付账单截图联系我退款。 - 购买功能后只能在当前机器使用么?
在线阅读功能购买后是跟utools账号绑定的,只要登录了你的已购该功能的账号的机器,就都能使用该功能。只要utools对你账号登录设备没有限制,那这个功能也没有登录设备限制,理论上一次购买之后,你就可以在任意机器上使用该功能。 - 为什么无法添加书源
有这种疑问的朋友,一般都是没搞清书源是啥样的,建议仔细阅读前文。再次提一下,暂不支持阅读3.0的书源哦。 - 怎么更新书源
如果是使用的摸鱼阅读官方书源,那么只需要在添加书源处输入官方书源地址,点击添加书源,就能自动更新本地书源,该新增的新增该修改的修改。
json书源同理,插件也会自动检测书源是否存在,是否有更新,并且自动更新到本地书源。
(建议定期删除所有书源,重新添加,因为更新操作不会删除掉失效的书源)
书源收集
官方书源持续更新中,大家有自己制作好的书源或者有不错的网站分享,都可以在下方评论区留言。好的书源我这边会收录到官方书源中,好的网站我会尽量制作成书源收录到官方书源。
当然如果有有能力的朋友自己制作整理了一套书源,并且上传到了服务器,也可以在评论区留下你的在线书源地址,给大家借鉴使用。
兄弟们,现在的书源有哪些不完善的,比如说有哪些正文垃圾内容没有过滤掉的,或者分章有问题的都可以提出来哈。还有大家有啥常用的觉得资源不错的网站,都在评论区留言哈。大家要多提供建议我才知道应该添加哪些网站的书源。


评论区